8 Gene Expression
Learning Objectives
After exploring this chapter, you should be able to
- Describe how DNA stores genetic information using nucleotide sequences.
- Describe the processes of transcription and translation as outlined in the Central Dogma.
- Identify the roles of mRNA, tRNA, ribosomes (rRNA), and amino acids in protein synthesis.
- Explain how the genetic code translates nucleotide sequences into amino acids.
- Define alleles and explain their role in gene expression and phenotypic variation.
In both prokaryotes and eukaryotes, the second function of DNA (the first was replication) is to provide the information needed to construct the proteins necessary so that the cell can perform all of its functions. The flow of genetic information in cells is summarized by the central dogma of molecular biology, which states that DNA encodes RNA, and RNA encodes protein (Figure 1). Proteins carry out most of the structural and functional roles in cells, so gene expression is central to life.
Lecture Video: The flow of genetic information, the Central Dogma of gene expression, transcription, and mRNA processing
The Central Dogma: DNA Encodes RNA; RNA Encodes Protein
The flow of genetic information in cells from DNA to mRNA to protein is described by the central dogma (Figure 1), which states that genes specify the sequences of mRNAs, which in turn specify the sequences of proteins.
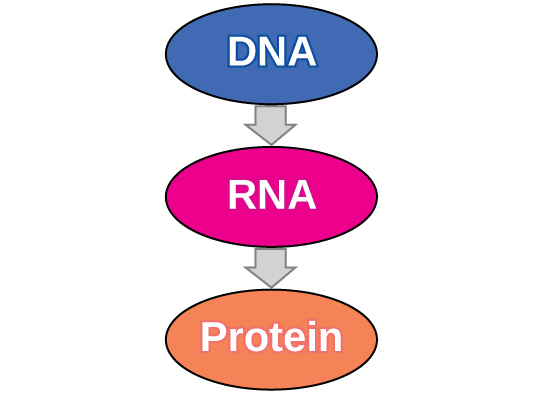
The copying of DNA to mRNA is relatively straightforward, with one nucleotide being added to the mRNA strand for every complementary nucleotide read in the DNA strand. The translation to protein is more complex because groups of three mRNA nucleotides correspond to one amino acid of the protein sequence. However, as we shall see in the next module, the translation to protein is still systematic, such that nucleotides 1 to 3 correspond to amino acid 1, nucleotides 4 to 6 correspond to amino acid 2, and so on.
Transcription: from DNA to mRNA
Both prokaryotes and eukaryotes perform fundamentally the same process of transcription, with the important difference of the membrane-bound nucleus in eukaryotes. With the genes bound in the nucleus, transcription occurs in the nucleus of the cell and the mRNA transcript must be transported to the cytoplasm. The prokaryotes, which include bacteria and archaea, lack membrane-bound nuclei and other organelles, and transcription occurs in the cytoplasm of the cell. In both prokaryotes and eukaryotes, transcription occurs in three main stages: initiation, elongation, and termination.
Initiation
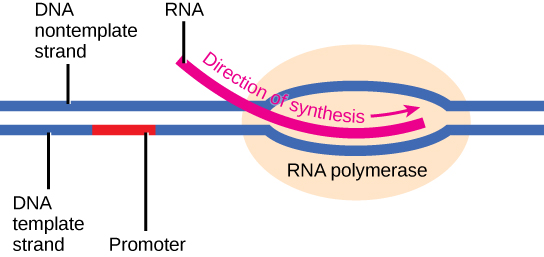
Transcription requires the DNA double helix to partially unwind in the region of mRNA synthesis. The region of unwinding is called a transcription bubble. The DNA sequence onto which the proteins and enzymes involved in transcription bind to initiate the process is called a promoter. In most cases, promoters exist upstream of the genes they regulate. The specific sequence of a promoter is very important because it determines whether the corresponding gene is transcribed all of the time, some of the time, or hardly at all (Figure 2).
Elongation
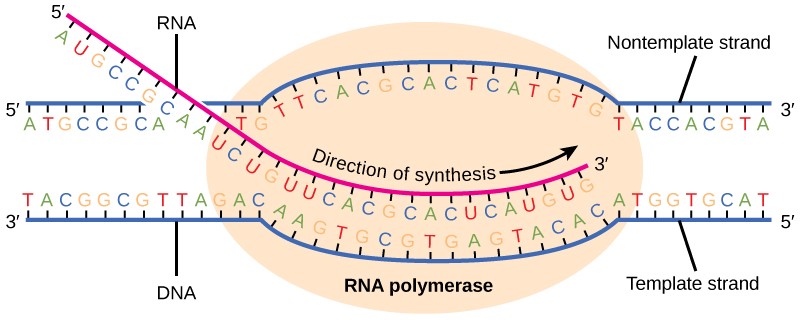
Transcription always proceeds from one of the two DNA strands, which is called the template strand. The mRNA product is complementary to the template strand and is almost identical to the other DNA strand, called the nontemplate strand, with the exception that RNA contains a uracil (U) in place of the thymine (T) found in DNA. During elongation, an enzyme called RNA polymerase proceeds along the DNA template adding nucleotides by base pairing with the DNA template in a manner similar to DNA replication, with the difference that an RNA strand is being synthesized that does not remain bound to the DNA template. As elongation proceeds, the DNA is continuously unwound ahead of the core enzyme and rewound behind it (Figure 3).
Termination
Once a gene is transcribed, the prokaryotic polymerase needs to be instructed to dissociate from the DNA template and liberate the newly made mRNA. Depending on the gene being transcribed, there are two kinds of termination signals, but both involve repeated nucleotide sequences in the DNA template that result in RNA polymerase stalling, leaving the DNA template, and freeing the mRNA transcript.
On termination, the process of transcription is complete. In a prokaryotic cell, by the time termination occurs, the transcript would already have been used to partially synthesize numerous copies of the encoded protein because these processes can occur concurrently using multiple ribosomes (polyribosomes) (Figure 4). In contrast, the presence of a nucleus in eukaryotic cells precludes simultaneous transcription and translation.
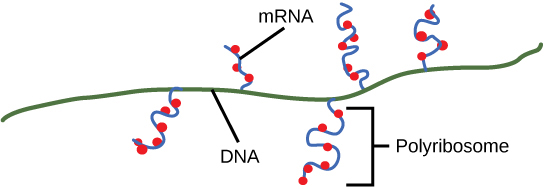
Translation
The synthesis of proteins is one of a cell’s most energy-consuming metabolic processes. In turn, proteins account for more mass than any other component of living organisms (with the exception of water), and proteins perform a wide variety of the functions of a cell. The process of translation, or protein synthesis, involves decoding an mRNA message into a polypeptide product. Amino acids are covalently strung together in lengths ranging from approximately 50 amino acids to more than 1,000.
Lecture Video: Translation and the genetic code
The Protein Synthesis Machinery
In addition to the mRNA template, many other molecules contribute to the process of translation. The composition of each component may vary across species; for instance, ribosomes may consist of different numbers of ribosomal RNAs (rRNA) and polypeptides depending on the organism. However, the general structures and functions of the protein synthesis machinery are comparable from bacteria to human cells. Translation requires the input of an mRNA template, ribosomes, tRNAs, and various enzymatic factors (Figure 5).
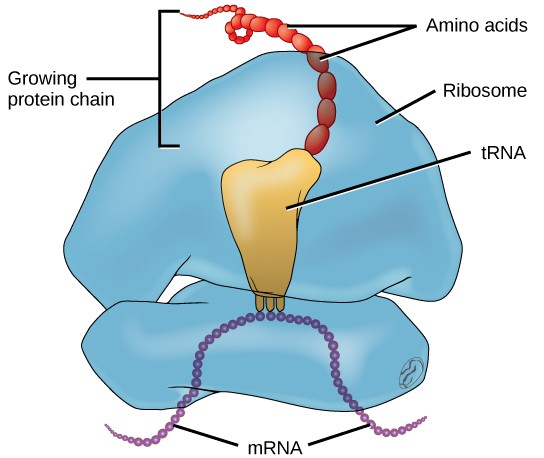
In E. coli, there are 200,000 ribosomes present in every cell at any given time. A ribosome is a complex macromolecule composed of structural and catalytic rRNAs, and many distinct polypeptides. In eukaryotes, the nucleolus is completely specialized for the synthesis and assembly of rRNAs.
Ribosomes are located in the cytoplasm in prokaryotes and in the cytoplasm and endoplasmic reticulum of eukaryotes. Ribosomes are made up of a large and a small subunit that come together for translation. The small subunit is responsible for binding the mRNA template, whereas the large subunit sequentially binds tRNAs, a type of RNA molecule that brings amino acids to the growing chain of the polypeptide. Each mRNA molecule is simultaneously translated by many ribosomes, all synthesizing protein in the same direction.
Depending on the species, 40 to 60 types of tRNA exist in the cytoplasm. Serving as adaptors, specific tRNAs bind to sequences on the mRNA template and add the corresponding amino acid to the polypeptide chain. Therefore, tRNAs are the molecules that actually “translate” the language of RNA into the language of proteins. For each tRNA to function, it must have its specific amino acid bonded to it. In the process of tRNA “charging,” each tRNA molecule is bonded to its correct amino acid.
The Genetic Code
To summarize what we know to this point, the cellular process of transcription generates messenger RNA (mRNA), a mobile molecular copy of one or more genes with an alphabet of A, C, G, and uracil (U). Translation of the mRNA template converts nucleotide-based genetic information into a protein product. Protein sequences consist of 20 commonly occurring amino acids; therefore, it can be said that the protein alphabet consists of 20 letters. Each amino acid is defined by a three-nucleotide sequence called the triplet codon. The relationship between a nucleotide codon and its corresponding amino acid is called the genetic code.
Given the different numbers of “letters” in the mRNA and protein “alphabets,” combinations of nucleotides corresponded to single amino acids. Using a three-nucleotide code means that there are a total of 64 (4 × 4 × 4) possible combinations; therefore, a given amino acid is encoded by more than one nucleotide triplet (Figure 6).
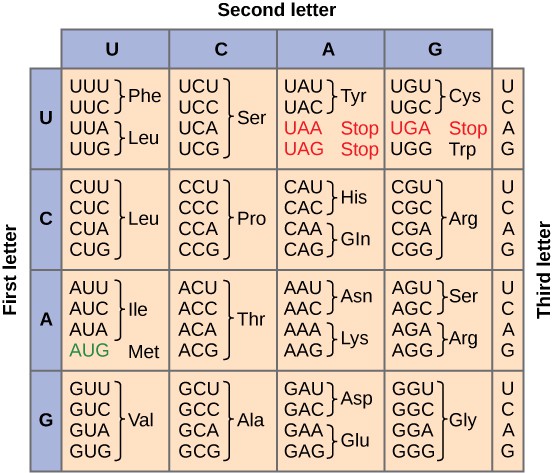
Three of the 64 codons terminate protein synthesis and release the polypeptide from the translation machinery. These triplets are called stop codons. Another codon, AUG, also has a special function. In addition to specifying the amino acid methionine, it also serves as the start codon to initiate translation. The reading frame for translation is set by the AUG start codon near the 5′ end of the mRNA. The genetic code is universal. With a few exceptions, virtually all species use the same genetic code for protein synthesis, which is powerful evidence that all life on Earth shares a common origin.
The Mechanism of Protein Synthesis
Just as with mRNA synthesis, protein synthesis can be divided into three phases: initiation, elongation, and termination. The process of translation is similar in prokaryotes and eukaryotes. Here we will explore how translation occurs in E. coli, a representative prokaryote, and specify any differences between prokaryotic and eukaryotic translation.
Protein synthesis begins with the formation of an initiation complex. In E. coli, this complex involves the small ribosome subunit, the mRNA template, three initiation factors, and a special initiator tRNA. The initiator tRNA interacts with the AUG start codon, and links to a special form of the amino acid methionine that is typically removed from the polypeptide after translation is complete.
In prokaryotes and eukaryotes, the basics of polypeptide elongation are the same, so we will review elongation from the perspective of E. coli. The large ribosomal subunit of E. coli consists of three compartments: the A site binds incoming charged tRNAs (tRNAs with their attached specific amino acids). The P site binds charged tRNAs carrying amino acids that have formed bonds with the growing polypeptide chain but have not yet dissociated from their corresponding tRNA. The E site releases dissociated tRNAs so they can be recharged with free amino acids. The ribosome shifts one codon at a time, catalyzing each process that occurs in the three sites. With each step, a charged tRNA enters the complex, the polypeptide becomes one amino acid longer, and an uncharged tRNA departs. The energy for each bond between amino acids is derived from GTP, a molecule similar to ATP (Figure 7). Amazingly, the E. coli translation apparatus takes only 0.05 seconds to add each amino acid, meaning that a 200-amino acid polypeptide could be translated in just 10 seconds.
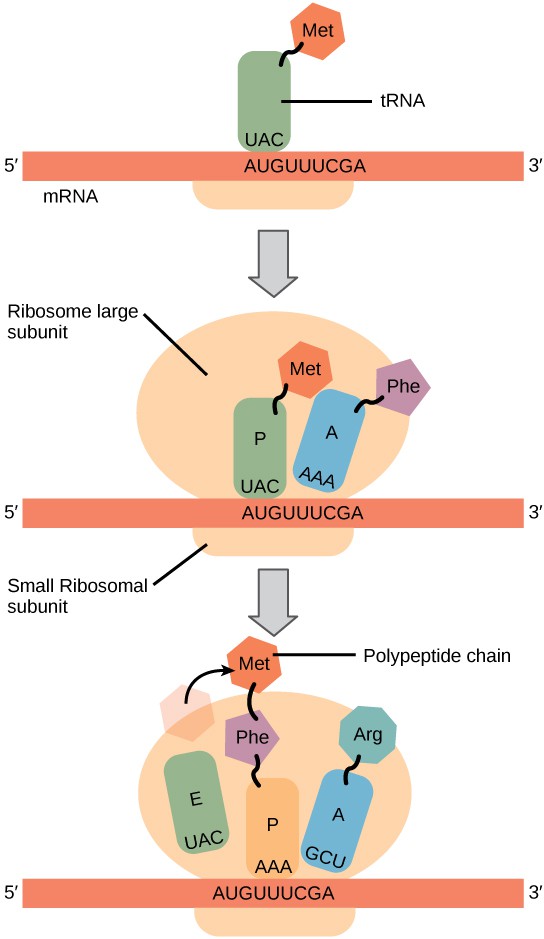
Termination of translation occurs when a stop codon (UAA, UAG, or UGA) is encountered. When the ribosome encounters the stop codon, the growing polypeptide is released and the ribosome subunits dissociate and leave the mRNA. After many ribosomes have completed translation, the mRNA is degraded so the nucleotides can be reused in another transcription reaction.
Additional Resources
Gene Expression in Action 🧬
Practice practice transcribing and translating a gene to protein using this online interactive tool.
Visualization Gene Expression
Alleles, Genetic Variation, and Phenotypes
While all humans share the same set of genes, individuals carry different versions of those genes called alleles. Alleles differ in their DNA sequence, which can, in turn, affect the protein they produce. Even a single nucleotide change can alter the amino acid sequence of a protein.
Some differences among alleles may have little or no effect, but others can change protein structure or function, which can lead to phenotypic variation. For example, alleles of the hemoglobin gene produce slightly different forms of the hemoglobin protein. In some cases, like sickle cell anemia, the change in protein structure has significant effects on health (Figure 8).
Thus, the processes of transcription and translation are the first step in how genetic variation at the DNA level can result in variation at the organismal level.

Glossary
- allele: a different version of a gene, distinguished by its DNA sequence.
amino acid: the building blocks of proteins, 20 different molecules that are linked into polypeptides.
anticodon: a three-nucleotide sequence in tRNA that pairs with a complementary mRNA codon.
central dogma: the concept that DNA encodes RNA, and RNA encodes protein.
codon: three consecutive nucleotides in mRNA that specify an amino acid or a stop signal.
elongation: stage of transcription or translation in which nucleotides or amino acids are added to the growing chain.
genetic code: the correspondence between codons in mRNA and amino acids in proteins.
initiation: the beginning stage of transcription or translation.
mRNA (messenger RNA): RNA that carries the code for a protein from the DNA to the ribosome.
phenotypic variation: observable differences among individuals in traits, often arising from differences in gene expression.
polypeptide: a chain of amino acids linked together that folds into a functional protein.
promoter: a DNA sequence where RNA polymerase binds to initiate transcription.
ribosome: a cellular structure composed of rRNA and proteins, the site of protein synthesis.
RNA polymerase (rRNA): the enzyme that synthesizes RNA from a DNA template.
stop codon: one of three codons (UAA, UAG, UGA) that signals termination of translation.
tRNA (transfer RNA): RNA molecule that carries a specific amino acid and matches it to the mRNA codon during translation.
translation: the process of synthesizing a protein from an mRNA sequence.
transcription: the process of synthesizing an RNA copy of a gene.
References and Resources
- Genetic Science Learning Center. (2016, March 1) Transcribe and Translate a Gene. Retrieved August 14, 2025, from https://learn.genetics.utah.edu/content/basics/txtl/
- Clark, M.A., Douglas, M., and Choi, J. 2018. Biology 2e. OpenStax. Retrieved from https://openstax.org/books/biology-2e/
