71 Origins of Organic Molecules in a Non-Reducing Atmosphere
A prebiotic non-reducing atmosphere is based on several assumptions:
- The early earth would have had insufficient gravity to hold H2 and other light gasses; thus “outgassing” would have resulted in a loss of H2 and other reducing agents from the atmosphere.
- Geological evidence suggests that the earth’s oceans and crust formed early in the Hadean Eon, just a few hundred million years after formation of the planet.
- Studies of 4.4 billion year old (early Hadean Eon) Australian zircon crystals suggest that their oxidation state is the same as modern day rocks, meaning that the early Hadean atmosphere was largely N2 and CO2, a distinctly non-reducing one! A colorized image of this Australian zircon is shown below.

So life might have begun in a non-reducing environment. Nevertheless, how far back can we date the appearance of the first actual cells on earth? Solid geological evidence of actual life dates to 3.5-3.95 billion years ago (i.e., the Archaean Eon). Softer evidence of microbial life exists in the form of graphite and other ‘possible’ remains as old as 4.1 billion years ago, near the end of the Hadean Eon. Thus, regardless of whether life began 3.5 or even 4.1 billion years ago, the evidence suggests that life’s beginnings had to contend with a non-reducing environment.
Before we look more closely at other evidence of life origins under non-reducing conditions, let’s consider the Panspermia, the possibility that life came to earth from extraterrestrial sources and a related hypothesis that prebiotic organic molecules came from extraterrestrial sources. Then we will examine how cells might have formed in localized, favorable terrestrial environments.
Panspermia – an Extraterrestrial Origin of Earthly Life
Panspermia posits that life itself arrived on our planet on comets or meteorites. Since these are unlikely to have sustained life in space, they must have been a kind of interstellar ‘mailbox’ into which dormant life forms were deposited. The cells in the mailboxes must have been cryptobiotic. Examples of cryptobiosis exist today (e.g., bacterial spores, brine shrimp!). Once delivered to earth’s life-friendly environment, such organisms would emerge from dormancy, eventually populating the planet. There is however, no evidence of dormant or cryptobiotic life on comets or meteorites, and no hard evidence to support Panspermia. On the other hand, there is evidence at least consistent with an extraterrestrial source of organic molecules, and plenty to support more terrestrial origins of life. In any case, notions of Panspermia (and even extraterrestrial sources of organic molecules) simply beg the question of the conditions that would have led to the origin of life elsewhere!
While panspermia is not a favored scenario, it is nevertheless intriguing, in the sense that it is in line the likelihood that organic molecules formed soon after the Big Bang. Moreover, if ready-made organic molecules and water were available, we can expect (and many do!) that there is life on other planets. This expectation has stimulated serious discussion and funding of programs looking for signs of life on other planets. For example, NASA funded Rover’s search for (and discovery of) signs of water on Mars. It even supported the more earth-bound Search for Extraterrestrial Intelligence (the SETI program), based on the assumption that life not only exists elsewhere, but that it evolved high level communication skills (and why not?!) Read The Martian Obsession for a fascinating story about meteorites from Mars that contain water and are worth more than gold.
Extraterrestrial Origins of Organic Molecules
Even if life did not come to us ready-made, could organic molecules have arrived on earth from outer space? They are abundant, for example in interstellar clouds, and could have become part of the earth as the planet formed around 4.8 billion years ago. This suggests that there was no need to create them de novo. One hypothesis suggests meteorites, comets and asteroids, known to contain organic molecules, brought them here during fiery impacts on our planet. Comet and meteorite bombardments would have been common 3.8 or more billion years ago. In this scenario the question of how (not on earth!) free energy and inorganic molecular precursors reacted to form organic molecules is moot!
A related hypothesis suggests that those fiery hits themselves provided the free energy necessary to synthesize the organic molecules from inorganic ones- a synthesis-on-arrival scenario. With this hypothesis on the one hand, we are back to an organic oceanic primordial soup. On the other, some have suggested that organic molecules produced in this way (not to mention any primordial life forms) would likely have been destroyed by the same ongoing impacts by extraterrestrial bodies; witness the relatively recent dinosaur extinction by an asteroid impact off the coast of Mexico some 65.5 million years ago.
See this video to learn more about life origins in a non-reducing atmosphere.
Organic Molecular Origins Closer to Home
Deep in the oceans, far from the meteoric bombardments and the rampant free energy of an oxygen-free and ozone-less sky, deep-sea hydrothermal vents would have been spewing reducing molecules (e.g., H2S, H2, NH4, CH4), much as they do today. Some vents are also high in metals such as lead, iron, nickel, zinc copper, etc. When combined with their clay or crustal substrata, these minerals could have provided catalytic surfaces to enhance organic molecule synthesis. Could such localized conditions have been the focus of prebiotic chemical experimentation leading to the origins of life? Let’s look at two kinds of deep-sea hydrothermal vents recognized today: volcanic and alkaline.
1. Origins in a High-Heat Hydrothermal Vent (Black Smoker)
The free energy available from a volcanic hydrothermal vent would come from the high heat (temperatures ranging to 350oC) and the minerals and chemicals expelled from the earth’s mantle. A volcanic hydrothermal vent is illustrated below.

Conditions assumed for prebiotic volcanic hydrothermal vents could have supported catalytic syntheses of organic molecules from inorganic precursors (see Volcanic Vents and organic molecule formation). The catalysts would have been metallic (nickel, iron, etc.) minerals. Chemical reactions tested include some that are reminiscent of biochemical reactions in chemoautotrophic cells alive today. Günter Wächtershäuser proposed the Iron-sulfur world theory of life’s origins in these vents, also called “black smokers”. These vents now spew large amounts of CH4 and NH4 and experiments favor the idea that iron-sulfur aggregates in and around black smokers could provide catalytic surfaces for the prebiotic formation of organic molecules like methanol and formic acid from dissolved CO2 and the CH4 and NH4 coming from the vents. Wächtershäuser is also credited with the idea that prebiotic selection acted not so much on isolated chemical reactions, but on aggregates of metabolic reactions.
We might think of such metabolic aggregates as biochemical pathways or multiple integrated pathways. Wächtershäuser proposed the selection of cyclic chemical reactions that released free energy usable by other reactions. This prebiotic metabolic evolution of reaction chemistries (rather than a simpler chemical evolution) would have been essential to the origins of life. A variety of extremophiles (e.g., thermophilic archaea) now living in and around black smokers seems to be testimony to black smoker origins of life.
While the idea of selecting metabolic pathways has great merit, there are problems with a life-origins scenario in volcanic hydrothermal vents. For one thing, their high temperatures would have destroyed as many organic molecules as were created. Also, the extremophilic archaea now found around these volcanic vents cannot be the direct descendants of any cells that might have originated there. Woese’s phylogeny clearly shows that archaea share a lineage with eukaryotes (not eubacteria – see above). Therefore, extremophilic cellular life originating in the vents must have first have given rise to a more moderate LUCA before then dying off themselves, after which extremophiles would once again evolve independently to re-colonize the vents! This mitigates against an extremophiles- first origins scenario. Given these concerns, recent proposals focus on life origins in less extreme alkaline hydrothermal vents.
2. Origins in an Alkaline Deep-Sea Vent (White Smoker)
Of the several scenarios discussed here, an origin of autotrophic life in alkaline vents is one of the more satisfying alternatives to a soupy origin of heterotrophic cells. For starters, at temperatures closer to 100oC -150oC, alkaline vents (white smokers) are not nearly as hot as are black smokers. An alkaline vent is shown below (Figure 3).

Other chemical and physical conditions of alkaline vents are also consistent with an origins-of-life scenario dependent on metabolic evolution. For one thing, the interface of alkaline vents with acidic ocean waters has the theoretic potential to generate many different organic molecules [Shock E, Canovas P. (2010) The potential for abiotic organic synthesis and biosynthesis at seafloor hydrothermal systems. Geofluids 10 (1-2):161-92)]. In laboratory simulations of alkaline vent conditions, the presence of dissolved CO2 favors serpentinization, a reaction of water and heat with serpentinite, an ironcontaining mineral found on land and in the oceanic crust. A sample of serpentinite is shown below (Figure 4).

Experimental serpentinization produces hydrocarbons and a warm aqueous oxidation of iron produces H2 that could account for abundant H2 in today’s white smoker emissions. Also, during serpentinization, a mineral called olivine [(Mg+2 , Fe+2)2SiO4] reacts with dissolved CO2 to form methane (CH4). So, the first precondition of life, the energetically favorable creation of organic molecules, is possible in alkaline vents.
Proponents of cellular origins in a late-Hadean non-reducing ocean also realized that organic molecules formed in an alkaline (or any) vent would disperse and be rapidly neutralized in the wider acidic oceans waters. Somehow, origins on a nonreducing planet had to include some way to contain newly formed organic molecules from the start, and to power further biochemical evolution. What then, were the conditions in an alkaline vent that could have contained organic molecules and led to metabolic evolution and ultimately, life’s origins? Let’s consider an intriguing proposal that gets at an answer!
The porous rock structure of today’s alkaline vents provides micro-spaces or micro-compartments that might have captured alkaline liquids emitted by white smokers. It turns out that conditions in today’s alkaline vents also support the formation of hydrocarbon biofilms. Micro-compartments lined with such biofilms could have formed a primitive prebiotic membrane against a rocky “cell wall”, within which alkaline waters would be trapped. The result would be a natural proton gradient between the alkaline solutions of organic molecules trapped in the microcompartments and the surrounding acidic ocean waters. Did all this happen?
Perhaps! Without a nutrient-rich environment, heterotrophs-first is not an option. That leaves only the alternate option: an autotrophs-first scenario for the origins of life. Nick Lane and his coworkers proposed that proton gradients were the selective force behind the evolution of early metabolic chemistries in the alkaline vent scenario (Prebiotic Proton Gradient Energy Fuels Origins of Life). Organized around biofilm compartments, prebiotic structures and chemistries would have harnessed the free energy of the natural proton gradients. In other words, the first protocells, and then cells, may have been chemoautotrophs.
Last but not least, how might chemoautotrophic chemistries on a non-reducing planet have supported polymer formation, as well as polymer replication? Today we see storage and replication of information in nucleic acids as separate from enzymatic catalysis of biochemical reactions. But are they all that separate? If replication is the faithful reproduction of the information needed for a cell, then enzymatic catalysis ensures the redundant production of all molecules essential to make the cell! Put another way, if catalyzed polymer synthesis is the replication of the workhorse molecules that accomplish cellular tasks, then what we call ‘replication’ is nothing more than the replication of nucleic acid information needed to faithfully reproduce these workhorse molecules. So, was there an early, coordinated, concurrent selection of mechanisms for the catalyzed metabolism as well as catalyzed polymer synthesis and replication? We’ll return to these questions shortly, when we consider the origins of life in an RNA world.
Life-origins in a non-reducing (and oxygen-free) atmosphere raise additional questions. Would proton gradients provide enough free energy to fuel and organize life’s origins? If so, how did cells arising from prebiotic chemiosmotic metabolism actually harness the energy of a proton gradient? Before life, were protocells already able to transduce gradient free energy into chemical free energy? And was ATP selected to hold chemical free energy from the start? Alternatively, was the relief of the gradient coupled at first to the synthesis of other high-energy intermediate compounds with e.g., thioester linkages? Later on, how did cells formed in alkaline vents escape the vents to colonize the rest of the planet?
Regardless of how proton gradient free energy was initially captured, the chemoautotrophic LUCA must have already have been using membrane-bound proton pumps and an ATPase to harness gradient free energy to make ATP, since all of its descendants do so. Finally, when did photoautotrophy (specifically oxygenic photoautotrophy) evolve? Was it a late evolutionary event? Is it possible that photosynthetic cells evolved quite early among some of the chemoautotrophic denizens of the white smokers, biding their time before exploding on the scene to create our oxygenic environment?
3. Heterotrophs-First vs. Autotrophs-First: Some Evolutionary Considerations
In the alkaline vent scenario, chemiosmotic metabolism predated life. Therefore, the first chemoautotrophic cells did not need the fermentative reactions required by cells in a heterotrophs-first origin scenario. Even though all cells alive today incorporate a form of glycolytic metabolism, glycolysis may not be the oldest known biochemical pathway, as we have thought for so long.
In support of a later evolution of glycolytic enzymes, those of the archaea show little structural resemblance to those of bacteria. If fermentative heterotrophy was a late evolutionary development, then LUCA and its early descendants would lack a well-developed glycolytic pathway. Instead, the LUCA must have been one of many ‘experimental’ autotrophic cells, most likely a chemoautotroph deriving free energy from inorganic chemicals in the environment. To account for heterotrophy in the three domains of life, it must have evolved separately in the two antecedent branches descending from the last universal common ancestor of bacterial, archaeal and eukaryotic organisms. The phylogeny shown below illustrates the autotrophs-first scenario.
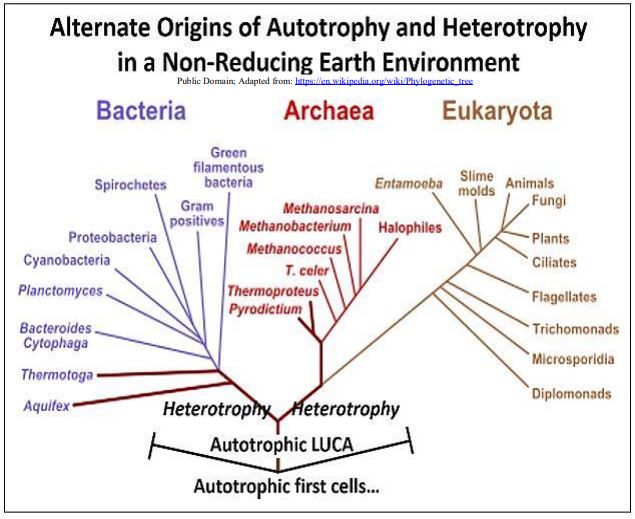
4. Summing Up
Speculation about life’s origins begins by trying to identify a source of free energy with which to make organic molecules. The first cells might have been heterotrophs formed in a reducing earth environment, from which autotrophs later evolved. On the other hand, the earliest cells may have been autotrophs formed under non-reducing conditions in the absence of a primordial soup. Then, only after these autotrophs had produced enough nutrient free energy to sustain them did heterotrophs belatedly emerge. Discoveries suggesting that the earth’s atmosphere was a non-reducing one more that 4 billion years ago (soon after the formation of the planet), and that there was life on earth 3.95 billion years ago favor metabolic origins of autotrophic life in a thermal vent, likely an alkaline vent. Questions nevertheless remain about life-origins under non-reducing conditions. Even the composition of the prebiotic atmosphere is still in contention (see Non-reducing earth- Not so fast!).
For now, let us put these concerns aside for a moment and turn to events that get us from the LUCA and its early descendants to the elaborated chemistries common to all cells today. The descriptions that follow are educated guesses about pathways taken early on towards the familiar cellularity now on earth. They mainly address the selection of catalytic mechanisms, replicative metabolism, the web of intersecting biochemical pathways, and the even more intricate chemical communication that organized cell function and complexity.
See this video to learn about phylogenetic support for autotrophs-first origins of life.
This chapter by Gerald Bergtrom is licensed CC BY 4.0.
