Perception and Action
129 Pre-attentive Vision
Learning Objectives
Know what we can perceive without attention and what we will miss when first directing our eyes.
Be able to describe what bottom-up salience and scene gist mean.
Know how subsequent saccades are directed by a combination of salience and top-down knowledge.
Pre-attentive vision refers to the visual information that is subconsciously processed, detected, sensed but not perceived by our brain. This is an important feature of our visual system, because it allows us to get information without spending the entirety of attention.(2019, Wolfe & Utochkin)
A scene gist is a brief scenery, sometimes without attention, that the brain processes to obtain the essence of what the scenery is about. It can let you determine with a short glance of the scenery whether what you are seeing is indoors/outdoors, an animal/person, a mountain/sea, and basic geometries. Without attention, we can perceive the scene gist of our surroundings, but not any details that may be perceived upon closer attention.
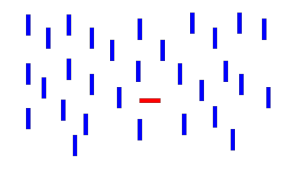
Bottom-up salience, or saliency, refers to a subjective quality that allows some items to ‘pop’, visually distinct from its neighboring objects. The core of visual salience is a bottom-up, stimulus-driven signal that announces “this location is sufficiently different from its surroundings to be worthy of your attention”. Many objects are observed along with its neighboring objects. The brain observes the target object’s orientation and separates the object from the neighboring objects with differing orientations.

While your first saccade in a scene will be made toward individual features of objects and contrasting luminescence, intensity, etc. (salient locations), subsequent saccades are directed by a combination of salience and top-down knowledge. The top-down knowledge influences saccades depending on what your goals are for looking at the scene (a person, building, etc).
Exercises
- Which two phrases fill in the blanks most properly? While looking at a scene with bottom-up salience, the brain focuses more on ___________, whereas with top-down knowledge, the brain focuses more on ________.
A. gathering all the information; the colors and shapes in the scene
B. individual features; the surrounding context
C. what you are expecting to see; what you are not expecting to see
D. the bottom of what you are seeing; the top of what you are seeing
Answer: B
Cheryl Olman PSY 3031 Detailed Outline
Provided by: University of Minnesota
Download for free at http://vision.psych.umn.edu/users/caolman/courses/PSY3031/
License of original source: CC Attribution 4.0
References:
Laurent Itti (2007) Visual salience. Scholarpedia, 2(9):3327.
Wolfe, J. M., & Utochkin, I. S. (2019). What is a preattentive feature?. Current opinion in psychology, 29, 19–26. https://doi.org/10.1016/j.copsyc.2018.11.005
